
Devops Culture
Within the context of Software Engineering, we can observe that over time there have been many different ways to develop and deliver software. The constant evolution means that today software engineers can practically produce without typing a single line of code, thanks to artificial intelligence technologies, and deliver software knowing only the basics of infrastructure, thanks to platforms that offer infra as a service.
DevOps Fundamentals
But it was not always like this. Developing and delivering required practically 100% manual work, carried out by teams that worked separately. We can trace back to the 2000s the idea of the waterfall model, where the development team and the operations team acted separately and with many conflicts. That was the traditional way.
The waterfall model consists of sequential development: capturing requirements, creating a design on top of that, implementing via code, testing, deploying, and ensuring maintenance.
Conflicts arose in very specific ways:
Team silos represent the total physical and functional separation between development and operations teams. Each team worked with its own tools, causing functional isolation.
The wall of confusion is where there was possibly no concern about reaching an agreement between teams on problems that arose. The developer would finish the code, throw it over the wall to operations and say: "it works on my machine."
Goal conflicts where one team focused on constantly creating new features and the other focused on keeping the system stable, and for that reason new features were identified as a risk.
Communication basically only happened when there was something to fix. No structured feedback, no shared visibility.
And because of the sequential and linear nature of the waterfall model, it was necessary to avoid going back to a previous step so as not to waste time. Therefore, problems would probably only be spotted after a long time. Perhaps anticipating testing and automation could have solved this, but that was only thought about much later.
The Agile Manifesto
Still thinking about code, and about how to improve the mess in the waterfall model, we can see that these conflicts were caused by people and not just by bugs. People, then, are what matter most above all else.
In February 2001, 17 developers gathered in Snowbird, Utah, and launched the Agile Manifesto, a document that proposed a change in mindset before being a change in process.
The manifesto is built around 4 core values:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
Notice that the items on the right are not eliminated; they still have value. What the manifesto says is that the ones on the left are worth more.
In practice, this means: small and frequent deliveries instead of one massive release after a year; continuous customer feedback instead of a frozen requirements document; self-organized and motivated teams instead of cogs in a machine.
The human factor is now being observed. So that people would not be treated as resources in a gear system, motivation and trust must now be the foundation. An approach based on culture and values is introduced, not just a list of processes.
Agile solved much of the problem within development. But it created a new problem: with faster and more frequent deliveries, the operations team became overwhelmed with far more code to manage across bureaucratic and manual infrastructures. Agile focused on "what to do." But now it was necessary to think about "how to deliver and maintain."
Ladies and gentlemen, introducing... DevOps!
A guy named Patrick Debois also noticed this, but it was back in 2009. He organized an event called DevOpsDays, in Ghent, Belgium, specifically to discuss the problems and solutions for Agile in production.
In 2009, the term emerged that was needed for a culture where the operations team would also have its voice heard, with a real understanding between the two teams, a union so that everything could be comprehended. The name could not have been anything other than DevOps.
DevOps as a philosophy, culturally acts on three pillars that the DevOps Handbook calls The Three Ways:
First Way - Flow: thinking about work as a continuous system, from development to the end user, eliminating bottlenecks and waste along the way.
Second Way - Feedback: creating fast and constant feedback loops. If something broke in production, the team needs to know about it in minutes, not days. Fast feedback means fast correction.
Third Way - Continuous Learning: creating a culture where failure is acceptable as long as you learn from it. Experiment, measure, improve, repeatedly.
People do not just participate in something by interacting and communicating with customers, keeping software running and delivering things all the time. They are collaborating and sharing responsibility. Everyone "speaks the same language," which is code. And it is through code that simplicity and the ease of producing and delivering must become increasingly efficient, with each individual being responsible for what they are going to do.
Automation Is Necessary
Here is the point that transforms DevOps from a good idea into a real advantage: automation.
Imagine that every commit to the repository automatically triggers a sequence of actions: the code is compiled, tests are executed, vulnerabilities are checked, and the result is packaged and delivered to an environment. None of these steps depend on someone manually opening a terminal.
The benefits are direct:
Speed: tasks that used to take hours or days now take minutes. A deployment that required a manual 40-step runbook becomes a button, or not even that, it becomes something that just happens automatically.
Reliability: humans make mistakes, especially on repetitive tasks under pressure. An automated pipeline executes the same process the same way every single time. No "I forgot to restart the service," no "I copied the wrong file."
Traceability: when everything is in code, everything has a history. Who changed what, when, and why. This applies to both the application code and the infrastructure.
Time freed up for what matters: when mechanical work is automated, engineers have time to learn, experiment, improve systems, and think about architecture, instead of spending the afternoon doing manual deployments.
Early feedback: if a test fails, you know in minutes. If a vulnerability is introduced, the pipeline detects it before it reaches production. The problem is found when it is still cheap to fix.
CI/CD
Across 8 phases, it is possible to have code developed, built, tested, audited, and packaged into versions. That is CI (Continuous Integration). And in practice, fully testing that code by deploying it to production environments (simulated or not), or delivering it directly to the world, whether manually or automatically, that is CD (Continuous Delivery or Continuous Deployment).
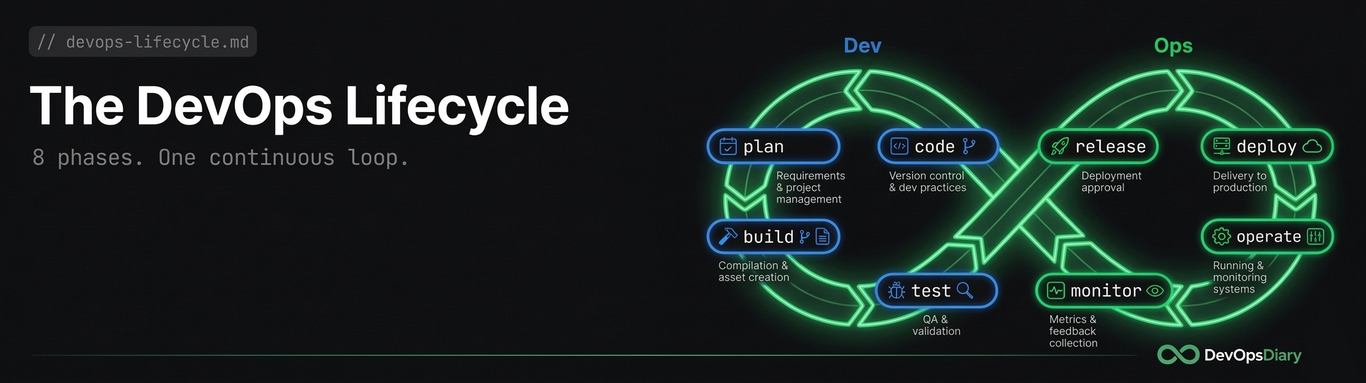
We call the 8 phases the DevOps Lifecycle:
Plan -> Code -> Build -> Test -> Release -> Deploy -> Operate -> Monitor
It is in the CD stage that some delivery strategies are also refined, such as:
- Blue/Green: two identical environments, one active and one on standby. The new version goes up in the standby, and traffic is redirected instantly. Need to roll back? Just redirect traffic back, a matter of seconds.
- Canary: the new version is delivered to a small slice of users first. If it works well, it expands gradually. If it breaks, the impact was minimal.
- Rolling: gradual update of servers, one by one, without taking the service down.
Considering Security in the Pipeline
Further ahead I will cover what is called DevSecOps. Personally I prefer to say that you do not need to change the name, you simply need to think and consider that security must be on your mind from the moment the technology professional turns on the computer to the moment the user closes the software, whenever possible.
It is possible to adopt security within the CI/CD pipeline so that code is validated after being tested and audited, before it is even delivered to production. Observing whether vulnerabilities are found, whether risks of information exposure are present, whether malicious installations exist, and so on, are techniques to apply security.
In other tasks on devopsdiary.site we will look into security issues in CI/CD.
The DevOps Tool Ecosystem
To make the entire CI/CD pipeline work across the 8 phases, it is necessary to use tools that have emerged for each need:
| Category | Tools |
|---|---|
| Source control | Git, GitHub, GitLab |
| CI/CD | GitHub Actions, GitLab CI, Jenkins, CircleCI |
| Configuration management | Ansible, Chef, Puppet |
| Containerization | Docker, Podman |
| Orchestration | Kubernetes |
| IaC | Terraform, CloudFormation |
| Monitoring | Prometheus, Grafana, ELK Stack |
Thinking About DevOps Beyond the Human Factor, but Also the Organizational One
You do not have DevOps without being inside a place where there is something that needs to be done, whether it is our job or our own startup. We have something to do for those who need it, and that is business.
DevOps practices in the organizational environment can strategically help in terms of costs and productivity. It is worth mentioning here, among all the practices considered in the field of administration for an organization to do things right, books like The Goal (theory of constraints), Accelerate (scientific data on engineering team performance), The Phoenix Project, and The DevOps Handbook serve as a way to think about DevOps as an organizational factor.
A Case Study on DevOps Adoption: Netflix
Speaking of organizations, there is Netflix, which adopted DevOps after a problem in its monolithic system that suffered a severe database corruption in 2008, forcing them to migrate to microservices on AWS over several years. That problem, instead of being ignored, was embraced, leading Netflix to create techniques focused on failures.
The so-called Chaos Engineering made Netflix not only change its architecture by implementing DevOps practices across its technology teams, but go even further: new failures were intentionally designed and applied so that systems could have greater resilience (Chaos Monkey, 2011).
It is by thinking about the worst possible destruction scenario that automated processes keep Netflix's systems always alive. Practically an army was built so that anything could be destroyed and rebuilt in record time. This made failures cheap, and the ROI on resilient systems allowed the company to have more and more users always using the streaming service, complaining only about what they are watching, perhaps.
- Agile Manifesto - https://agilemanifesto.org/
- The Netflix Simian Army - https://netflixtechblog.com/the-netflix-simian-army-16e57fbab116